This shows you how the Ethereum Virtual Machine works, and how to reverse engineer a smart contract.
To disassemble the smart contract, I am using Trail of Bits’ Ethersplay plugin for Binary Ninja. If you find this post useful, follow my Twitter. I post more content like this there.
[BLOG] Reversing Ethereum Smart Contracts (using @trailofbits's Ethersplay plugin) https://t.co/dShP6zwq2l
— Brandon Arvanaghi (@arvanaghi) March 20, 2018
Ethereum Virtual Machine
The Ethereum Virtual Machine (EVM) is stack-based and quasi-Turing complete.
1) Stack based: Rather than relying on registers, any operation will be entirely contained within the stack. Operands, operators, and function calls all get placed on the stack, and the EVM understands how act on that data and make the smart contract execute.
Ethereum uses Postfix Notation to implement its stack-based implementation. What this means, in very simplified terms, is that the last operator to get pushed on the stack will act on the data pushed onto the stack before it.
An example: we are programmed to understand the format of 2 + 2. In our head, we know the operator (+) in the middle means we want to apply addition on 2 and 2. Putting + inbetween the two operands is just one way of representing what we want to have take place: we could just as easily represent this as 2 2 +, which is Postfix.
2) quasi-Turing complete: A language or code execution engine is said to be “Turing complete” when it can solve any problem you provide it. It doesn’t matter how long it takes so long as it can theoretically solve it. The Bitcoin Scripting Language is not Turing complete, because there are very few things you can do with it.
In the EVM, you can solve everything, but we say quasi-Turing complete because you are limited by cost. Because anyone issuing a transaction must pay a price per gas (or price per computational unit of that transaction), complex problems become enormously costly. Thus, while the EVM could solve any problem you feed it, the necessity of paying a gas price makes very complex problems economically infeasible.
Bytecode vs. Runtime Bytecode
When compiling a contract, you can either get the contract bytecode or the runtime bytecode.
The contract bytecode is the bytecode of what will actually end up sitting on the blockchain PLUS the bytecode needed for the transaction of placing that bytecode on the blockchain, and initializing the smart contract (running the constructor).
The runtime bytecode, on the other hand, is just the bytecode that ends up sitting on the blockchain. This does not include the bytecode needed to initialize the contract and place it on the blockchain.
Let’s take the Greeter.sol contract and examine the difference.
contract mortal {
/* Define variable owner of the type address */
address owner;
/* This function is executed at initialization and sets the owner of the contract */
function mortal() { owner = msg.sender; }
/* Function to recover the funds on the contract */
function kill() { if (msg.sender == owner) selfdestruct(owner); }
}
contract greeter is mortal {
/* Define variable greeting of the type string */
string greeting;
/* This runs when the contract is executed */
function greeter(string _greeting) public {
greeting = _greeting;
}
/* Main function */
function greet() constant returns (string) {
return greeting;
}
}
When compiled with solc --bin Greeter.sol to get the contract’s bytecode, we get:
6060604052341561000f57600080fd5b6040516103a93803806103a983398101604052808051820191905050336000806101000a81548173ffffffffffffffffffffffffffffffffffffffff021916908373ffffffffffffffffffffffffffffffffffffffff1602179055508060019080519060200190610081929190610088565b505061012d565b828054600181600116156101000203166002900490600052602060002090601f016020900481019282601f106100c957805160ff19168380011785556100f7565b828001600101855582156100f7579182015b828111156100f65782518255916020019190600101906100db565b5b5090506101049190610108565b5090565b61012a91905b8082111561012657600081600090555060010161010e565b5090565b90565b61026d8061013c6000396000f30060606040526004361061004c576000357c0100000000000000000000000000000000000000000000000000000000900463ffffffff16806341c0e1b514610051578063cfae321714610066575b600080fd5b341561005c57600080fd5b6100646100f4565b005b341561007157600080fd5b610079610185565b6040518080602001828103825283818151815260200191508051906020019080838360005b838110156100b957808201518184015260208101905061009e565b50505050905090810190601f1680156100e65780820380516001836020036101000a031916815260200191505b509250505060405180910390f35b6000809054906101000a900473ffffffffffffffffffffffffffffffffffffffff1673ffffffffffffffffffffffffffffffffffffffff163373ffffffffffffffffffffffffffffffffffffffff161415610183576000809054906101000a900473ffffffffffffffffffffffffffffffffffffffff1673ffffffffffffffffffffffffffffffffffffffff16ff5b565b61018d61022d565b60018054600181600116156101000203166002900480601f0160208091040260200160405190810160405280929190818152602001828054600181600116156101000203166002900480156102235780601f106101f857610100808354040283529160200191610223565b820191906000526020600020905b81548152906001019060200180831161020657829003601f168201915b5050505050905090565b6020604051908101604052806000815250905600a165627a7a723058204138c228602c9c0426658c0d46685e1d9c157ff1f92cb6e28acb9124230493210029
When compiled with solc --bin-runtime Greeter.sol to only get the runtime bytecode, we get:
60606040526004361061004c576000357c0100000000000000000000000000000000000000000000000000000000900463ffffffff16806341c0e1b514610051578063cfae321714610066575b600080fd5b341561005c57600080fd5b6100646100f4565b005b341561007157600080fd5b610079610185565b6040518080602001828103825283818151815260200191508051906020019080838360005b838110156100b957808201518184015260208101905061009e565b50505050905090810190601f1680156100e65780820380516001836020036101000a031916815260200191505b509250505060405180910390f35b6000809054906101000a900473ffffffffffffffffffffffffffffffffffffffff1673ffffffffffffffffffffffffffffffffffffffff163373ffffffffffffffffffffffffffffffffffffffff161415610183576000809054906101000a900473ffffffffffffffffffffffffffffffffffffffff1673ffffffffffffffffffffffffffffffffffffffff16ff5b565b61018d61022d565b60018054600181600116156101000203166002900480601f0160208091040260200160405190810160405280929190818152602001828054600181600116156101000203166002900480156102235780601f106101f857610100808354040283529160200191610223565b820191906000526020600020905b81548152906001019060200180831161020657829003601f168201915b5050505050905090565b6020604051908101604052806000815250905600a165627a7a723058204138c228602c9c0426658c0d46685e1d9c157ff1f92cb6e28acb9124230493210029
As you can see, the runtime bytecode is a subset of the full contract bytecode.

Reversing
In this tutorial, we’ll be using Trail of Bits’ Ethersplay plugin for Binary Ninja to disassemble the bytecode.
We will be using the Greeter.sol contract from the Ethereum.org.
First, follow the instructions here on adding the Ethersplay plugin to Binary Ninja. As a reminder, we will only be reversing the runtime bytecode, since that will tell us what the contract actually does.
Initial View
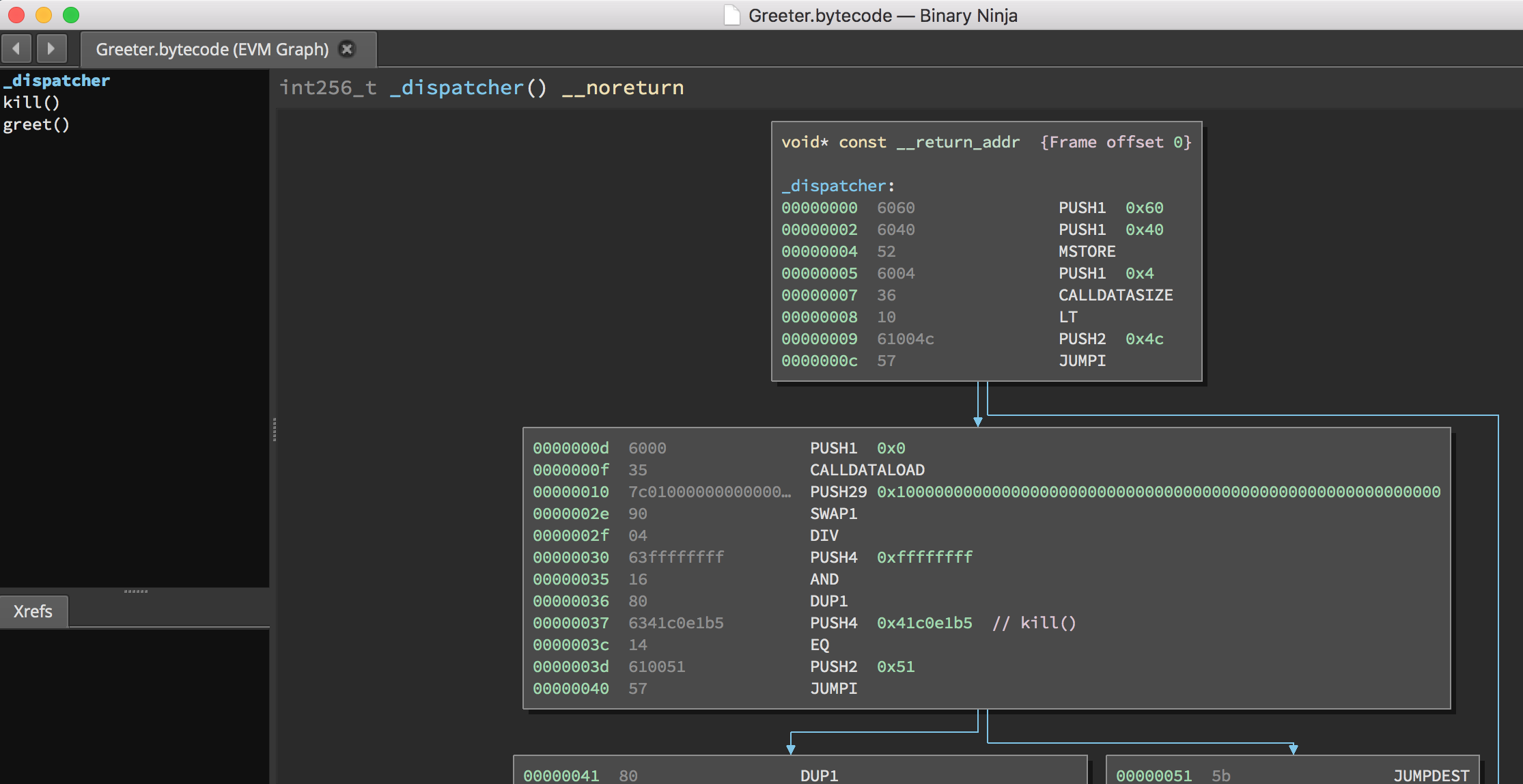
The Ethersplay plugin identifies all functions in the runtime bytecode and logically separates them for you. In our contract, Ethersplay discovered two functions: kill() and greet(). We’ll get into how these were extracted shortly.
First instructions
When you make a transaction to a smart contract, the first piece of code your transaction will interact with is that contract’s dispatcher. The dispatcher takes your transaction data and determines the function with which you are trying to interact.
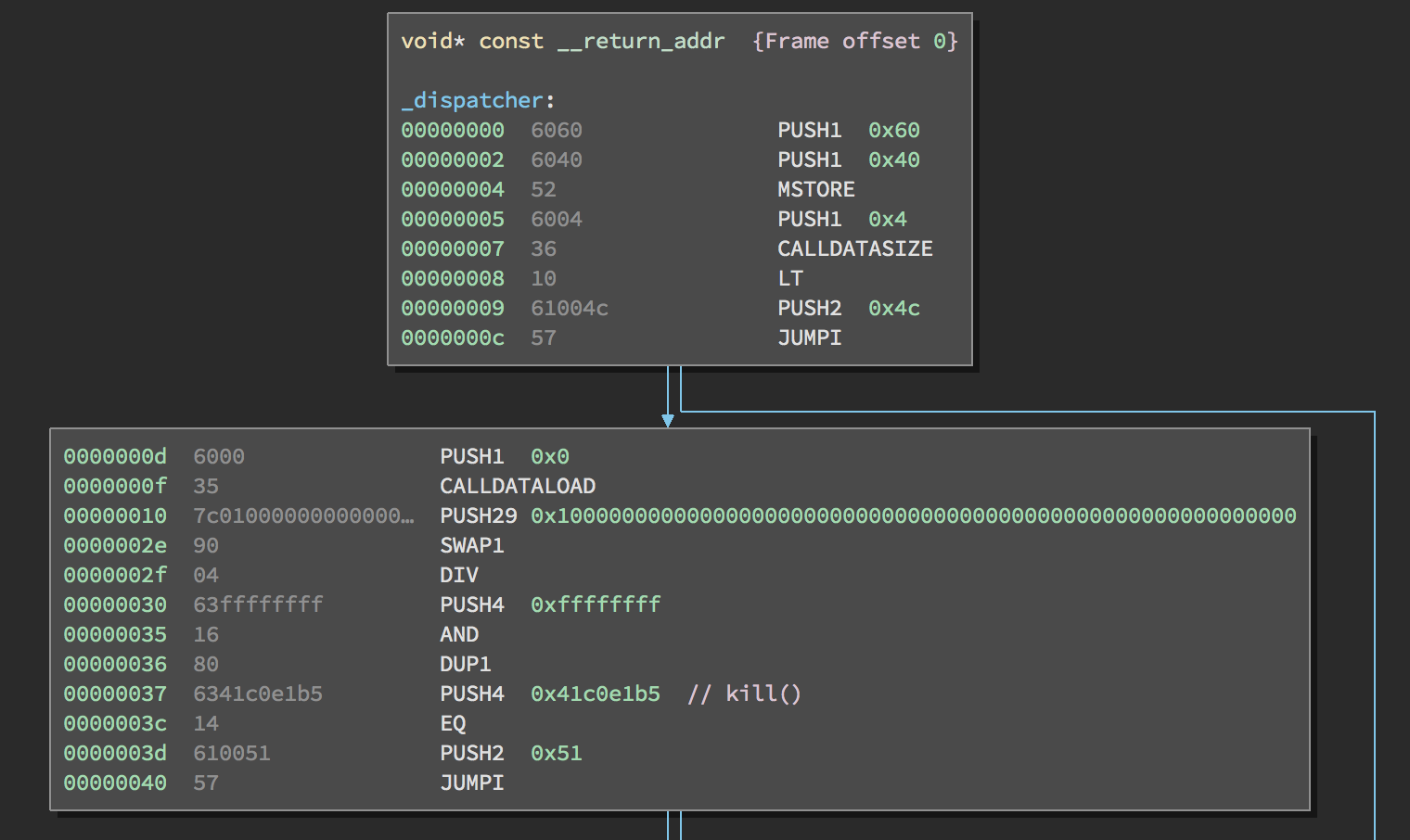
The first instructions we see in the dispatcher are:
PUSH1 0x60 // argument 2 of mstore: the value to store in memory
PUSH1 0x40 // argument 1 of mstore: where to store that value in memory
MSTORE // mstore(0x40, 0x60)
PUSH1 0x4
CALLDATASIZE
LT
PUSH2 0x4c
JUMPI
There are 16 different versions of the PUSH instruction (PUSH1… PUSH16). The number tells the EVM how many bytes we are pushing onto the stack.
The first two instructions, PUSH1 0x60 and PUSH1 0x40, push the byte 0x60 and the byte 0x40 onto the stack, respectively. After these instructions complete, the runtime stack will look like this:
1: 0x40
0: 0x60
MSTORE is defined in Solidity’s documentation like so:
| Instruction | Result |
|---|---|
| mstore(p, v) | mem[p..(p+32)) := v |
Function arguments are read in from the top of the stack to the bottom, meaning we get mstore(0x40, 0x60). This is equivalent to mem[0x40...0x40+32] := 0x60.
mstore pops two items off the stack, so the stack is now empty! Our next instruction are:
PUSH1 0x4
CALLDATASIZE
LT
PUSH 0x4c
JUMPI
After PUSH1 0x4, the stack has only one item.
0: 0x4
The CALLDATASIZE function pushes the size of the calldata (the equivalent of msg.data) onto the stack. You can send any data you want to any smart contract. CALLDATASIZE will just check to see how long that data is.
After the call to CALLDATASIZE, the stack looks like:
1: (however long the msg.data or calldata is)
0: 0x4
This next instruction is LT, short for “less than”, and works like so:
| Instruction | Result |
|---|---|
| mstore(p, v) | mem[p..(p+32)) := v |
| lt(x, y) | 1 if x < y, 0 otherwise |
lt pushes 1 onto the stack if the first argument is less than the second argument, and 0 if this is not the case. In our code, we get lt((however long the msg.data or calldata is), 0x4).
Why does the EVM check to see that our calldata is at least 4 bytes? Because of how function identifiers work.
Each function is identified by the first four bytes of its keccak256 hash. That is, you place the function prototype (the function name and what arguments it takes) into a keccak256 hash function. In our contract, we have:
keccak256("greet()") = cfae3217...
keccak256("kill()") = 41c0e1b5...
Thus, the function identifiers are cfae3217 for greet() and 41c0e1b5 for kill(). The dispatcher checks to see that the calldata (or message data) you sent to the contract is at least 4 bytes long to make sure you are actually trying to communicate with a function!
A function identifier is always 4 bytes long, so if the entire message you send the smart contract is less than 4 bytes, then there’s no function you could possibly be communicating with.
In fact, we can see how the smart contract kicks you out in our disassembly. If the calldatasize is less than 4 bytes, the bytecode immediately sends you to the block of code at the end, ending contract execution.
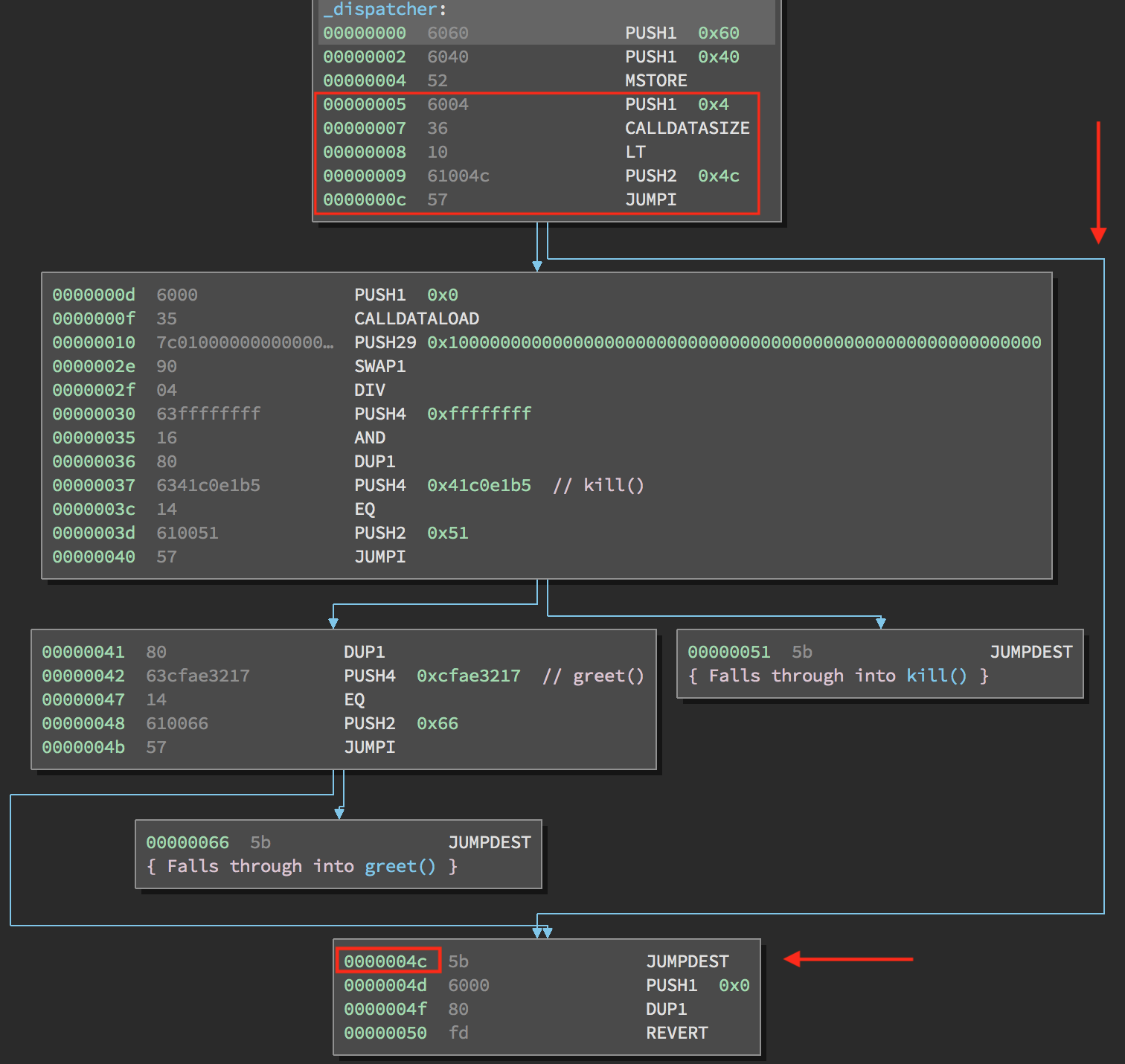
Let’s examine how this determination is made.
If lt((however long the msg.data or calldata is), 0x4) evaluates to 1 (true, or in other words, the calldata is less than 4 bytes), then after popping the top two values off the stack, lt pushes 1 onto the stack.
0: 1
Next, we have PUSH 0x4c and then JUMPI. After PUSH 0x4c, our stack looks like:
1: 0x4c
0: 1
JUMPI is jump if, and jumps to a certain label/location if a condition is met.
| Instruction | Result |
|---|---|
| mstore(p, v) | mem[p..(p+32)) := v |
| lt(x, y) | 1 if x < y, 0 otherwise |
| jumpi(label, cond) | jump to label if cond is nonzero |
In our case, the label is offset 0x4c in code, and the cond is 1, so it evaluated to true. This means the program jumps to offset 0x4c.
Dispatching
Let’s take a look at how the desired function is extracted from calldata. The stack is empty after the last JUMPI instruction.
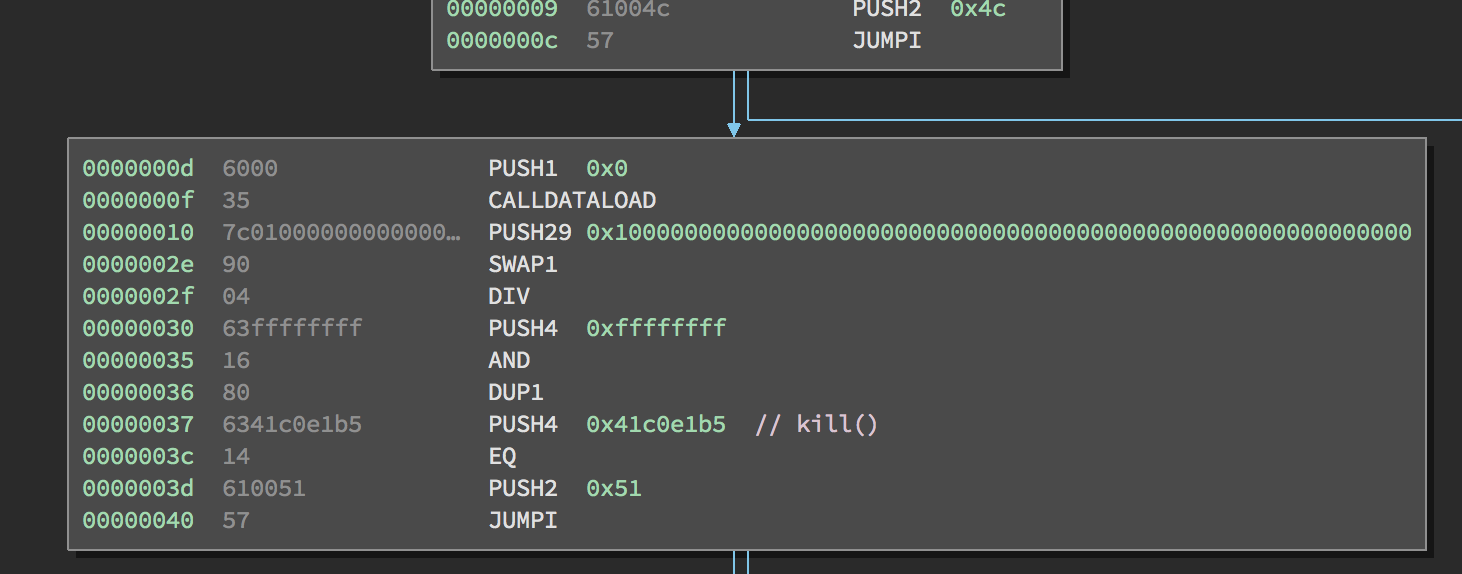
Here are the commands in the second block:
PUSH1 0x0
CALLDATALOAD
PUSH29 0x100000000....
SWAP1
DIV
PUSH4 0xffffffff
AND
DUP1
PUSH4 0x41c0e1b5
EQ
PUSH2 0x51
JUMPI
PUSH1 0x0 pushes 0 to the stop of the stack.
0: 0
CALLDATALOAD accepts as an argument an index within the calldata sent to the smart contract, and reads 32 bytes from that index, like so:
| Instruction | Result |
|---|---|
| mstore(p, v) | mem[p..(p+32)) := v |
| lt(x, y) | 1 if x < y, 0 otherwise |
| jumpi(label, cond) | jump to label if cond is nonzero |
| calldataload(p) | call data starting from position p (32 bytes) |
CALLDATALOAD pushes the 32 bytes it read onto the top of the stack. Since 0 was the index passed to it from the PUSH1 0x0 command, CALLDATALOAD reads 32 bytes of calldata starting at byte 0, and then pushes it to the top of the stack (after popping the original 0x0). The new stack is:
0: 32 bytes of calldata starting at byte 0
The next instruction is PUSH29 0x100000000....
1: 0x100000000....
0: 32 bytes of calldata starting at byte 0
SWAPi swaps the top item on the stack with the ith item after it. In this case, the instruciton is SWAP1, so it swaps the top item on the stack with the first one coming after it.
| Instruction | Result |
|---|---|
| mstore(p, v) | mem[p..(p+32)) := v |
| lt(x, y) | 1 if x < y, 0 otherwise |
| jumpi(label, cond) | jump to label if cond is nonzero |
| calldataload(p) | call data starting from position p (32 bytes) |
| swap1 … swap16 | swap topmost and ith stack slot below it |
1: 32 bytes of calldata starting at byte 0
0: PUSH29 0x100000000....
The next instruction is DIV, which becomes div(x, y) and thus x / y. In this case, x = 32 bytes of calldata starting at byte 0, and y = 0x100000000....
The 0x100000000.... is 29 bytes long, consisting of a 1 at the beginning, followed by all 0s. We read 32 bytes from calldata earlier. Dividing our 32 bytes of calldata by this 10000... will leave us only the topmost 4 bytes of our calldataload starting at index 0. These four bytes – the first four bytes in calldataload starting at index 0 – are the function identifier!
If this part isn’t clear to you, think of it like this: in base10, 123456000 / 100 = 123456. In base16, this is no different. Dividing a 32 byte value (in base 16) by a 29 byte value (16 ^ 29) will only keep the top 4 bytes.
The result of the DIV gets pushed on the stack.
0: function identifier from calldata
Next, we see PUSH4 0xffffffff then AND, which in our case will be ANDing 0xffffffff with the function identifier sent from calldata. This is done simply to 0 out the remaining 28 bytes after the function identifier in that same stack element.
A DUP1 instruction follows, which duplicates the first item on the stack (in this case, the function identifier), and pushes it on top of the stack:
1: function identifier from calldata
0: function identifier from calldata
Finally, we see PUSH4 0x41c0e1b5. This is the function identifier for kill(). We push it onto the stack because we want to compare it to what the calldata’s function identifier was.
2: 0x41c0e1b5
1: function identifier from calldata
0: function identifier from calldata
The next instruction is EQ, or eq(x, y), which pops x and y off the stack, pushes 1 onto the stack if they are equal or 0 otherwise. This is in essence the “dispatching” part of the dispatcher: testing for equality between the calldata function identifier and all function identifiers in the smart contract.
1: (1 if calldata functio identifier matched kill() function identifier, 0 otherwise)
0: function identifier from calldata
After PUSH2 0x51, we have:
2: 0x51
1: (1 if calldata functio identifier matched kill() function identifier, 0 otherwise)
0: function identifier from calldata
We push 0x51 because that is where we will jump in the program if the JUMPI condition is met. In other words, we jump to offset 0x51 in the code if the function identifier sent from calldata matched kill(), because 0x51 is where the kill() function lives!
After JUMPI, we have either gone to offset 0x51, or continued down program execution.
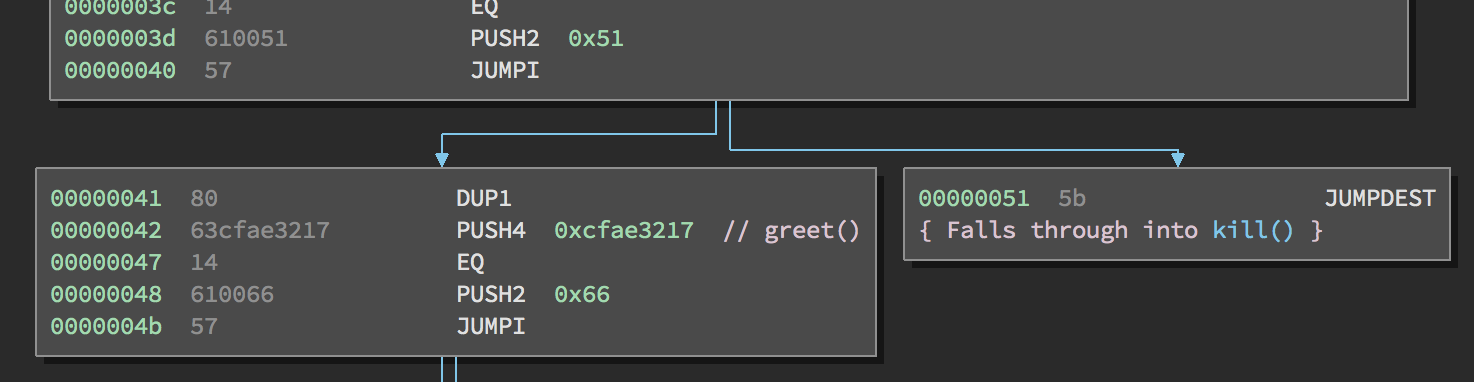
Our stack only contains:
0: function identifier from calldata
You’ll notice that if we do not jump to the kill() function, the dispatcher implements the same logic to compare the calldata function identifier with the greet() function identifier. The dispatcher will check against every function int he smart contract, and if it doesn’t find one that matches the identifier you sent, then it sends you to the exit block.
Part 2
Part 2 of this tutorial can be found here.
[BLOG] Reversing Ethereum Smart Contracts: Part 2 (using @trailofbits's Ethersplay plugin) https://t.co/zxklFq0LiL
— Brandon Arvanaghi (@arvanaghi) April 23, 2018
For more content on Ethereum and smart contracts, follow my Twitter, where I post more information like this.